Automatische Skalierung von Kubernetes-Cluster-Ressourcen auf OpenStack Magnum (CODE-DE)
Wenn die Autoskalierung von Kubernetes-Clustern aktiviert ist, kann das System
Ressourcen hinzufügen, wenn der Bedarf hoch ist, oder
nicht benötigte Ressourcen entfernen, wenn der Bedarf gering ist. So halten Sie die Kosten niedrig.
Der gesamte Prozess kann automatisch ablaufen, damit sich der Administrator auf wichtigere Aufgaben konzentrieren kann.
Dieser Artikel erklärt verschiedene Befehle zur Größenänderung oder Skalierung des Clusters und führt zu einem Befehl zur automatischen Erstellung eines autoskalierbaren Kubernetes-Clusters für OpenStack Magnum.
Was wir abdecken werden
Definitionen der horizontalen, vertikalen und Knoten-Skalierung
Definition der Autoskalierung bei der Erstellung des Clusters in der Horizon-Oberfläche
Definition der automatischen Skalierung bei der Erstellung des Clusters über die CLI
Abrufen von Cluster-Vorlagenbeschriftungen aus der Horizon-Oberfläche
Abrufen von Cluster-Vorlagenbezeichnungen über die Kommandozeile
Voraussetzungen
Nr. 1 Konto
Sie benötigen ein CODE-DE Hosting-Konto mit Horizon-Schnittstelle https://cloud.fra1-1.cloudferro.com/auth/login/?next=/.
Nr. 2 Erstellen von Clustern auf Kommadozeile
Der Artikel So verwenden Sie die Befehlszeilenschnittstelle für Kubernetes-Cluster auf CODE-DE OpenStack Magnum führt Sie in die Erstellung von Clustern über ein Kommandozeilen-Interface ein.
Nr. 3 Openstack-Client mit der Cloud verbinden
Bereiten Sie Openstack- und Magnum-Clients vor, indem Sie Schritt 2 OpenStack- und Magnum-Clients mit der Horizon Cloud verbinden aus dem Artikel Installation von OpenStack- und Magnum-Clients für die Befehlszeilenschnittstelle von CODE-DE Horizon ausführen
Nr. 4. Nodegroups umgestalten
Schritt 7 des Artikels Erstellen zusätzlicher Nodegroups in Kubernetes Cluster auf CODE-DE OpenStack Magnum zeigt ein Beispiel für die Größenänderung der Nodegroups für die automatische Skalierung.
Nr. 5 Bildung von Clustern
Schritt 2 des Artikels Erstellen eines Kubernetes-Clusters mit CODE-DE OpenStack Magnum zeigt, wie man Master- und Worker-Knoten für die automatische Skalierung definiert.
Es gibt drei verschiedene Autoscaling-Funktionen, die eine Kubernetes-Cloud bieten kann:
Horizontaler Pod-Autoscaler
Die horizontale Skalierung eines Kubernetes-Clusters bedeutet, dass die Anzahl der laufenden Pods je nach den tatsächlichen Anforderungen zur Laufzeit erhöht oder verringert wird. Zu berücksichtigende Parameter sind die Nutzung von CPU und Arbeitsspeicher sowie die gewünschte minimale und maximale Anzahl von Pod-Replikaten.
Die horizontale Skalierung wird auch als „scaling out“ bezeichnet und mit HPA abgekürzt.
Vertikaler Pod-Autoscaler
Vertikale Skalierung (oder „Aufwärtsskalierung“, VPA) ist das Hinzufügen oder Abziehen von Ressourcen zu bzw. von einem vorhandenen Rechner. Wenn mehr CPUs benötigt werden, fügen Sie sie hinzu. Wenn sie nicht benötigt werden, schalten Sie einige von ihnen ab.
Cluster-Autoscaler
HPA und VPA reorganisieren die Ressourcennutzung und die Anzahl der Pods. Es kann jedoch ein Zeitpunkt kommen, an dem die Größe des Systems selbst nicht mehr ausreicht, um die Nachfrage zu befriedigen. Die Lösung ist die automatische Skalierung des Clusters selbst, um die Anzahl der Knoten, auf denen die Pods laufen, zu erhöhen oder zu verringern.
Sobald die Anzahl der Knoten angepasst wird, müssen sich die Pods und andere Ressourcen ebenfalls automatisch im Cluster neu verteilen. Die Anzahl der Knoten stellt eine physische Barriere für die automatische Skalierung von Pods dar.
Alle drei Modelle der automatischen Skalierung können miteinander kombiniert werden.
Autoskalierung beim Erstellen eines Clusters definieren
Sie können bei der Definition eines neuen Clusters Parameter für die automatische Skalierung festlegen, indem Sie das Fenster Größe im Assistenten für die Erstellung von Clustern verwenden:
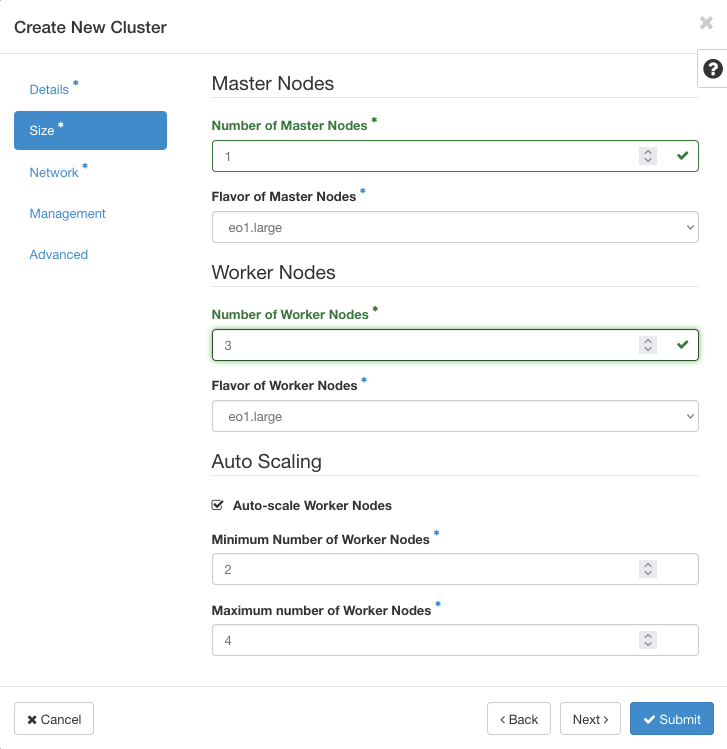
Geben Sie eine minimale und maximale Anzahl von Arbeitsknoten an. Wenn diese Werte 2 bzw. 4 sind, wird der Cluster zu jedem Zeitpunkt mindestens 2 und höchstens 4 Knoten haben. Wenn kein Datenverkehr für den Cluster vorliegt, wird er automatisch auf 2 Knoten skaliert. In diesem Beispiel kann der Cluster je nach Verkehrsaufkommen 2, 3 oder 4 Knoten haben.
Für den gesamten Prozess der Erstellung eines Kubernetes-Clusters in Horizon siehe Voraussetzungen Nr. 5.
Warnung
Wenn Sie sich bei der Definition eines Clusters für die Option NGINX Ingress entscheiden, wird NGINX Ingress als 3 Replikate auf 3 separaten Knoten ausgeführt. Dadurch wird die Mindestanzahl von Knoten in Magnum autoscaler außer Kraft gesetzt.
Automatische Skalierung von Knotengruppen zur Laufzeit
Der Autoscaler in Magnum verwendet Node Groups. Knotengruppen können verwendet werden, um Worker mit verschiedenen Flavors zu erstellen. Die Standard-Worker-Knotengruppe wird bei der Bereitstellung des Clusters automatisch erstellt. Knotengruppen haben untere und obere Grenzen für die Knotenanzahl. Mit diesem Befehl können Sie diese für einen bestimmten Cluster ausdrucken:
openstack coe nodegroup show NoLoadBalancer default-worker -f json -c max_node_count -c node_count -c min_node_count
Das Ergebnis wäre dann:
{
"node_count": 1,
"max_node_count": 2,
"min_node_count": 1
}
Dies funktioniert so lange gut, bis Sie versuchen, die Größe des Clusters über das in der Knotengruppe festgelegte Limit hinaus zu ändern. Wenn Sie versuchen, die Größe des obigen Clusters auf 12 Knoten zu ändern, etwa so:
openstack coe cluster resize NoLoadBalancer --nodegroup default-worker 12
erhalten Sie folgende Fehlermeldung:
Resizing default-worker outside the allowed range: min_node_count = 1, max_node_count = 2 (HTTP 400) (Request-ID: req-bbb09fc3-7df4-45c3-8b9b-fbf78d202ffd)
Um diesen Fehler zu beheben, ändern Sie node_group max_node_count manuell:
openstack coe nodegroup update NoLoadBalancer default-worker replace max_node_count=15
und ändern Sie dann die Größe des Clusters auf den gewünschten Wert, der in diesem Beispiel weniger als 15 beträgt:
openstack coe cluster resize NoLoadBalancer –nodegroup default-worker 12
Wenn Sie den ersten Befehl wiederholen:
openstack coe nodegroup show NoLoadBalancer default-worker -f json -c max_node_count -c node_count -c min_node_count
wird das Ergebnis nun mit einem korrigierten Wert angezeigt:
{
"node_count": 12,
"max_node_count": 15,
"min_node_count": 1
}
Wie Autoscaling die Obergrenze erkennt
Die erste Version von Autoscaling würde die aktuelle Obergrenze für Autoscaling in der Variable node_count nehmen und 1 dazu addieren. Wäre der Befehl zur Erstellung eines Clusters
openstack coe cluster create mycluster --cluster-template mytemplate --node-count 8 --master-count 3
würde diese Version von Autoscaler den Wert 9 (gezählt als 8 + 1) annehmen. Dieses Verfahren war jedoch nur auf die Standardarbeiterknotengruppe beschränkt.
Der aktuelle Autoscaler kann mehrere Knotengruppen unterstützen, indem er die Rolle der Knotengruppe erkennt:
openstack coe nodegroup show NoLoadBalancer default-worker -f json -c role
und das Ergebnis lautet
{
"role": "worker"
}
Solange die Rolle Arbeiter ist und max_node_count größer als 0 ist, wird der Autoscaler versuchen, die default-worker Knotengruppe zu skalieren, indem er 1 zu max_node_count addiert.
Achtung
Jede zusätzliche Knotengruppe muss das konkrete Attribut max_node_count enthalten.
Ausführliche Beispiele für die Verwendung der Befehlsfamilie openstack coe nodegroup finden Sie unter Voraussetzungen Nr. 4.
Automatisch skalierende Bezeichnungen für Cluster
Es gibt drei Bezeichnungen für Cluster, die die automatische Skalierung beeinflussen:
auto_scaling_enabled – wenn wahr, ist sie aktiviert
min_node_count – die minimale Anzahl von Knoten
max_node_count – die maximale Anzahl von Knoten zu einem beliebigen Zeitpunkt.
Bei der Definition von Clustern über die Horizon-Oberfläche richten Sie diese Cluster-Labels ein.
Listen Sie Cluster mit Container Infra => Cluster auf und klicken Sie auf den Namen des Clusters. Unter Labels finden Sie den aktuellen Wert für auto_scaling_enabled.

Wenn „true“ aktiviert ist, wird der Cluster automatisch skaliert..
Erstellen eines neuen Clusters mit CLI und aktivierter Autoskalierung
Der Befehl zum Erstellen eines Clusters mit CLI muss alle üblichen Parameter sowie alle Labels enthalten, die für die Funktion des Clusters erforderlich sind. Die Besonderheit der Syntax besteht darin, dass die Label-Parameter aus einer einzigen Zeichenfolge bestehen müssen, ohne Leerzeichen dazwischen.
This is what one such command could look like:
openstack coe cluster create mycluster
--cluster-template k8s-stable-1.23.5
--keypair sshkey
--master-count 1
--node-count 3
--labels auto_scaling_enabled=true,autoscaler_tag=v1.22.0,calico_ipv4pool_ipip=Always,cinder_csi_plugin_tag=v1.21.0,cloud_provider_enabled=true,cloud_provider_tag=v1.21.0,container_infra_prefix=registry-public.cloudferro.com/magnum/,eodata_access_enabled=false,etcd_volume_size=8,etcd_volume_type=ssd,hyperkube_prefix=registry-public.cloudferro.com/magnum/,k8s_keystone_auth_tag=v1.21.0,kube_tag=v1.21.5-rancher1,master_lb_floating_ip_enabled=true
Wenn Sie einfach versuchen würden, den Befehl zu kopieren und in das Terminal einzufügen, würden Sie Syntaxfehler erhalten. Das Ende der Zeile ist nicht erlaubt, der gesamte Befehl muss eine lange Zeichenkette sein. Um Ihnen das Leben zu erleichtern, finden Sie hier eine Version des Befehls, die Sie erfolgreich kopieren können.
Warnung
Die Zeile mit den Bezeichnungen ist auf dem Bildschirm nur teilweise sichtbar, aber sobald Sie sie in die Befehlszeile einfügen, wird sie von der Terminalsoftware problemlos ausgeführt.
Der Befehl lautet:
openstack coe cluster create mycluster –cluster-template k8s-stable-1.23.5 –keypair sshkey –master-count 1 –node-count 3 –labels auto_scaling_enabled=true,autoscaler_tag=v1.22.0,calico_ipv4pool_ipip=Always,cinder_csi_plugin_tag=v1.21.0/,cloud_provider_enabled=true,cloud_provider_tag=v1.21.0,container_infra_prefix=registry-public.cloudferro.com/magnum/,eodata_access_enabled=false,etcd_volume_size=8,etcd_volume_type=ssd,hyperkube_prefix=registry-public.cloudferro.com/magnum/,k8s_keystone_auth_tag=v1.21.0,kube_tag=v1.21.5-rancher1,master_lb_floating_ip_enabled=true,min_node_count=2,max_node_count=4
Der Name wird mycluster sein, ein Masterknoten und drei Arbeiterknoten am Anfang.
Bemerkung
Es ist zwingend erforderlich, die maximale Anzahl von Knoten für die automatische Skalierung festzulegen. Wird dies nicht angegeben, wird die max_node_count standardmäßig auf 0 gesetzt, und es findet überhaupt keine Autoskalierung für die jeweilige Knotengruppe statt.
Dies ist das Ergebnis nach der Erstellung:
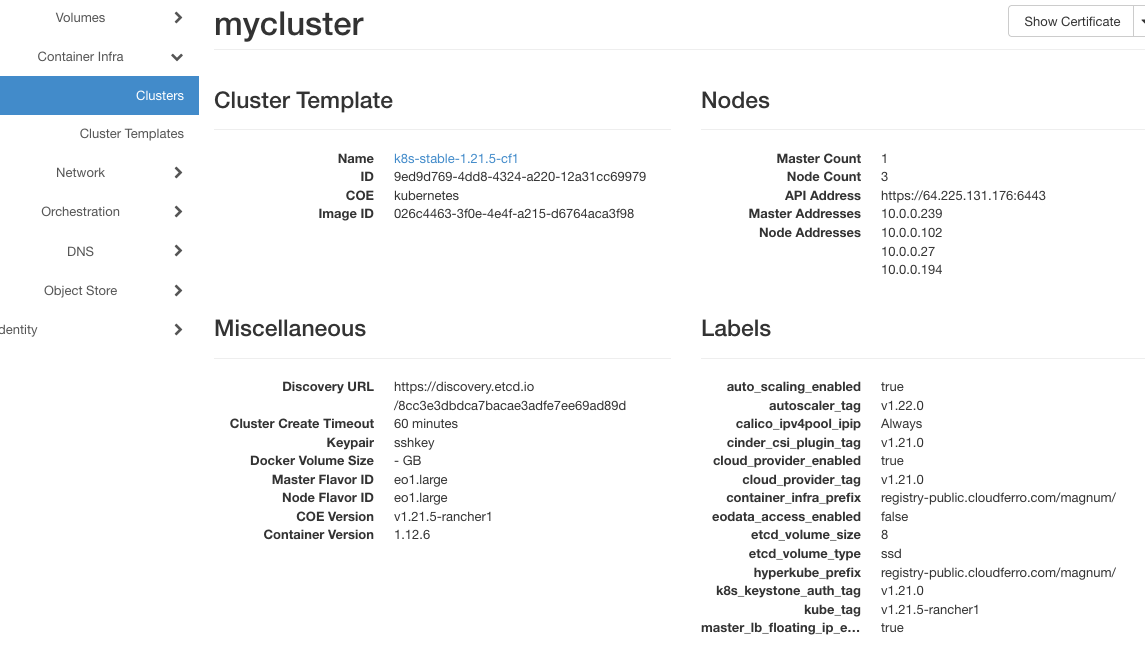
Drei Arbeitsknotenadressen sind aktiv: 10.0.0.102, 10.0.0.27, und 10.0.0.194.
Es gibt keinen Datenverkehr zum Cluster, so dass die automatische Skalierung sofort einsetzte. Eine oder zwei Minuten nach Abschluss der Erstellung sank die Anzahl der Arbeitsknoten um einen auf die Adressen 10.0.0.27 und 10.0.0.194 - das ist Autoscaling bei der Arbeit.
Nodegroups mit Worker Rolle werden automatisch skaliert
Autoscaler erkennt automatisch alle neuen Nodegroups mit zugewiesener „Worker“-Rolle. Die „Worker“-Rolle wird standardmäßig zugewiesen, wenn sie nicht angegeben wird. Die maximale Anzahl von Knoten muss ebenfalls angegeben werden.
Prüfen Sie zunächst, welche Nodegroups für den Cluster k8s-cluster vorhanden sind. Der Befehl lautet
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
Smit -c gibt an, welche Spalte angezeigt werden soll, wobei alle anderen Spalten, die nicht in dem Befehl aufgeführt sind, außer Acht gelassen werden. Sie werden eine Tabelle mit den Spalten Name, Node_count, Status und Role sehen, was bedeutet, dass Spalten wie uuid, flavor_id und image_id keinen wertvollen Platz auf dem Bildschirm einnehmen werden. Das Ergebnis ist eine Tabelle mit nur den vier Spalten, die für das Hinzufügen von Knotengruppen mit Rollen relevant sind:

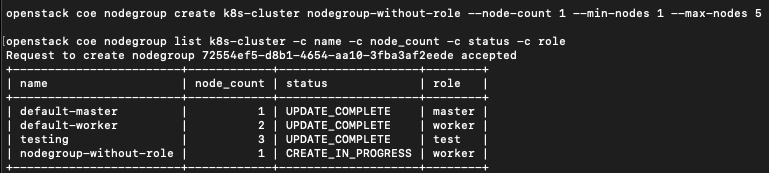
Fügen Sie nun eine Knotengruppe ohne Rolle hinzu und lassen sie ausgeben:
openstack coe nodegroup create k8s-cluster nodegroup-without-role --node-count 1 --min-nodes 1 --max-nodes 5
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
Da die Rolle nicht angegeben wurde, wurde der Knotengruppe Nodegroup-without-role der Standardwert „worker“ zugewiesen. Da das System so eingerichtet ist, dass Knotengruppen mit der Rolle Worker automatisch skaliert werden, wird die Knotengruppe automatisch skaliert, wenn Sie eine Knotengruppe ohne Rolle hinzufügen.
Fügen Sie nun eine Knotengruppe mit dem Namen Knotengruppe-mit-Rolle hinzu, und der Name der Rolle lautet custom.:
openstack coe nodegroup create k8s-cluster nodegroup-with-role --node-count 1 --min-nodes 1 --max-nodes 5 --role custom
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
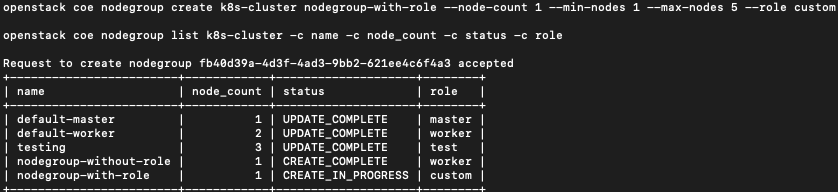
Dadurch wird eine Knotengruppe hinzugefügt, aber nicht automatisch skaliert, da keine Arbeiter-Rolle für die Knotengruppe angegeben ist.
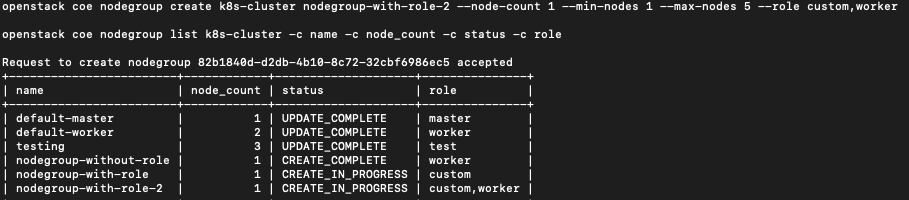
Fügen Sie schließlich eine Knotengruppe mit dem Namen Knotengruppe-mit-Rolle-2 hinzu, für die zwei Rollen in einer Anweisung definiert sind, nämlich sowohl Benutzer als auch Arbeiter. Da mindestens eine der Rollen Arbeiter ist, wird sie automatisch skaliert.
openstack coe nodegroup create k8s-cluster nodegroup-with-role-2 --node-count 1 --min-nodes 1 --max-nodes 5 --role custom,worker
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
Cluster k8s-cluster hat jetzt 8 Knoten:
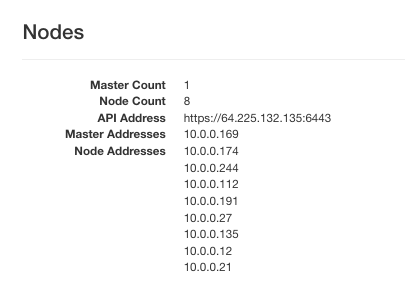
Sie können diese drei Cluster mit dem folgenden Befehlssatz löschen:
openstack coe nodegroup delete k8s-cluster nodegroup-with-role
openstack coe nodegroup delete k8s-cluster nodegroup-with-role-2
openstack coe nodegroup delete k8s-cluster nodegroup-without-role
Noch einmal das Ergebnis:
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
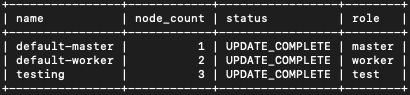
So erhalten Sie alle Etiketten von der Horizon-Schnittstelle
Wählen Sie Container Infra => Clusters und klicken Sie auf den Clusternamen. Sie erhalten einen einfachen Text im Browser. Kopieren Sie die Zeilen unter Labels und fügen Sie sie in einen Texteditor Ihrer Wahl ein.
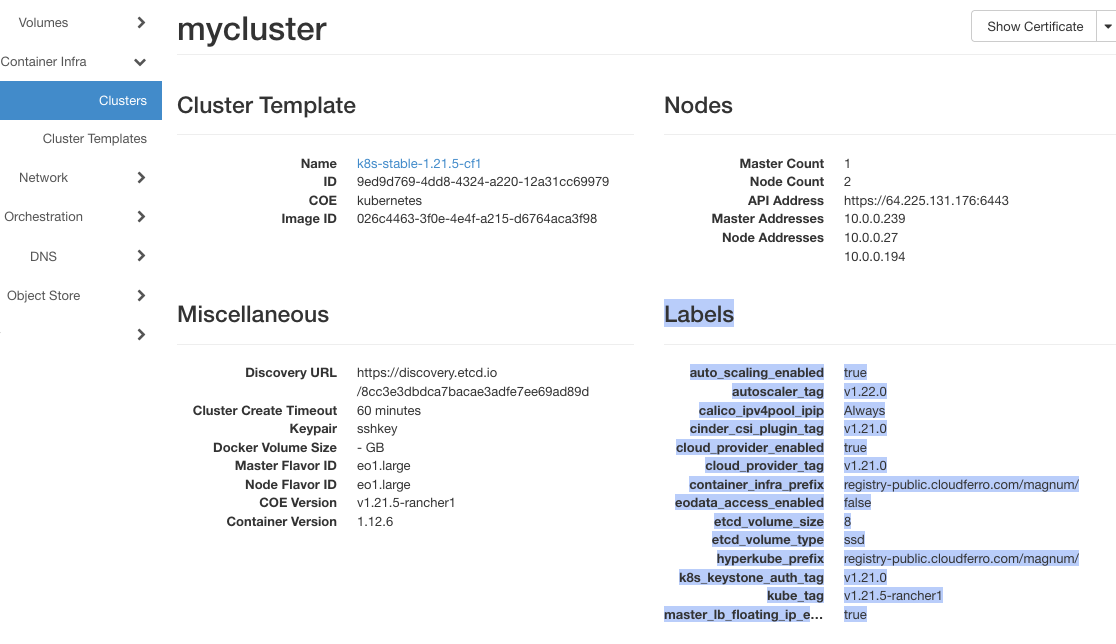
Entfernen Sie im Texteditor manuell die Zeilenenden und erstellen Sie eine Zeichenkette ohne Umbrüche und Zeilenumbrüche, und fügen Sie sie dann wieder in den Befehl ein.
So erhalten Sie alle Labels über die Kommandozeile
Es gibt einen speziellen Befehl, der Etiketten aus einem Cluster erzeugt:
openstack coe cluster template show k8s-stable-1.23.5 -c labels -f yaml
Dies ist das Ergebnis:
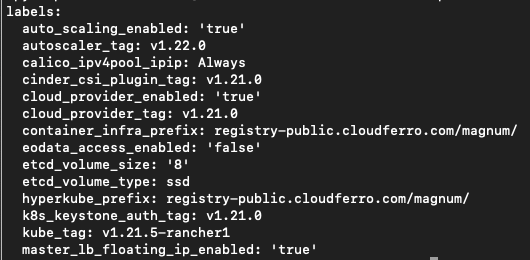
Das ist das Format yaml, wie durch den Parameter -f angegeben. Die Zeilen stellen Beschriftungswerte dar. Als Nächstes müssen Sie eine lange Zeichenfolge ohne Zeilenumbrüche wie im vorherigen Beispiel erstellen und dann den CLI-Befehl eingeben.
Labels String beim Erstellen von Clustern in Horizon verwenden
Lange Label-Strings können auch bei der manuellen Erstellung des Clusters, d. h. über die Horizon-Schnittstelle, verwendet werden. Die Stelle, an der diese Bezeichnungen einzufügen sind, wird in Schritt 4 Bezeichnungen definieren unter Voraussetzungen Nr. 2 beschrieben.
Was als nächstes zu tun ist
Die Autoskalierung ähnelt dem Autohealing von Kubernetes-Clustern, und beide bringen Automatisierung mit sich. Sie garantieren auch, dass das System sich selbst korrigiert, solange es sich innerhalb seiner Grundparameter befindet. Nutzen Sie die automatische Skalierung von Cluster-Ressourcen so oft wie möglich!