Zugriff auf EODATA von Kubernetes Pods in CODE-DE FRA1-1 Cloud mit boto3
Bei der Verwendung von Kubernetes auf CODE-DE Clouds möchten Sie vielleicht bald auf das EODATA Satellitenbild-Repository zugreifen.
Ein häufiger Anwendungsfall ist z. B. die Batch-Job-Verarbeitung, bei der Kubernetes-Pods den Download von EODATA-Bildern initiieren, um sie weiter zu verarbeiten.
Dieser Artikel erklärt, wie der EODATA-Zugriff auf OpenStack Magnum implementiert wird und verwendet die Python-Bibliothek boto3 für den Zugriff auf EODATA aus Kubernetes-Pods. Docker und DockerHub dienen zur Containerisierung und Bereitstellung der Anwendung, die auf EODATA zugreift.
Vorausetzungen
No. 1 Konto
Sie benötigen ein CODE-DE Konto mit Zugriff auf die Horizon-Schnittstelle: https://cloud.fra1-1.cloudferro.com/auth/login/?next=/.
No. 2 Kubernetes-Cluster mit Zugriff auf EODATA
Ein Kubernetes-Cluster auf der CODE-DE FRA1-1 Cloud erstellt mit Option „EODATA access enabled“. Siehe auch den Knowledge Base Artikel Erstellen eines Kubernetes-Clusters mit CODE-DE OpenStack Magnum.
No. 3 Kenntnis von kubectl
Weitere Hinweise finden Sie unter Zugriff auf Kubernetes-Cluster nach der Bereitstellung mit Kubectl auf CODE-DE OpenStack Magnum
No. 4 Kenntnisse über den Zugriff der boto3-Bibliothek auf EODATA
Um zu verstehen, wie man auf EODATA ohne Kubernetes zugreifen kann, lesen Sie diesen Artikel: Wie kann man EO-Daten von CREODIAS mit boto3 herunterladen?
Der Artikel, den Sie jetzt lesen, ist eigentlich der obige Artikel, übertragen auf die Kubernetes-Umgebung.
No. 5 Docker ist auf Ihrem Rechner installiert
Siehe dazu How to install and use Docker on Ubuntu 24.04.
No. 6 An account in DockerHub
Ein Konto bei DockerHub. Sie können auch andere Image-Registrierungen verwenden, aber das würde den Rahmen dieses Artikels sprengen.
Was wir tun werden
Bereitstellung von Hintergrundinformationen zur Verwendung von EODATA auf Magnum
Vorbereitung des Docker-Images einer Anwendung, die mit boto3 auf EODATA zugreift
Docker-Image erstellen und auf DockerHub veröffentlichen
Kubernetes-Pod mit Docker-Container starten und EODATA-Zugriff verifizieren
Step 1 Kubernetes-Cluster mit EODATA erstellen
Auf der CODE-DE FRA1-1 Cloud ist jedes Projekt standardmäßig mit einem EODATA-Netzwerk verbunden. Daher gibt es bei der Erstellung einer virtuellen Maschine in OpenStack eine Option zum Hinzufügen eines EODATA-Netzwerks zu einer solchen VM.
Da ein auf Magnum aufgebauter Kubernetes-Cluster aus denselben VMs erstellt wird, können Sie jedem Arbeitsknoten im Cluster Zugriff auf EODATA gewähren. Verwenden Sie die Befehle Infra → Cluster → Cluster erstellen, um die Erstellung eines Clusters zu starten, und markieren Sie das Kästchen „EODATA-Zugriff aktiviert“.
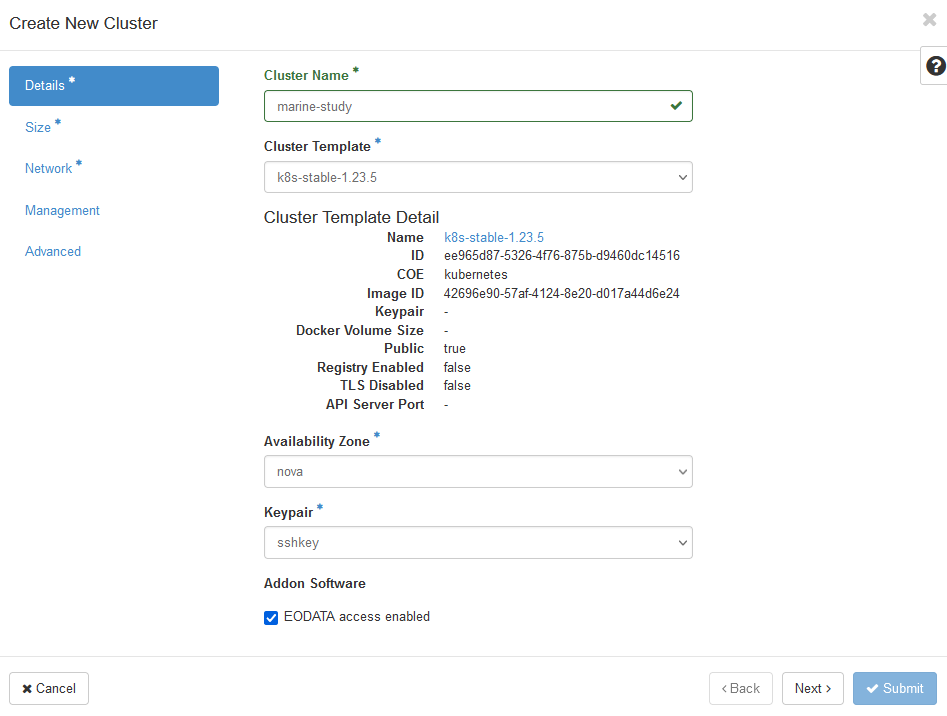
Nachdem die Erstellung des Clusters abgeschlossen ist, überprüfen Sie, ob die Knoten ordnungsgemäß mit EODATA verbunden wurden. Führen Sie Compute → Instanzen aus und überprüfen Sie, ob die IP-Adresse Ihrer Arbeitsknoten im EODATA-Netzwerk liegt. In der folgenden Abbildung ist marine-study der Name des Clusters und eodata_00341_3 der Name des EODATA-Netzwerks:
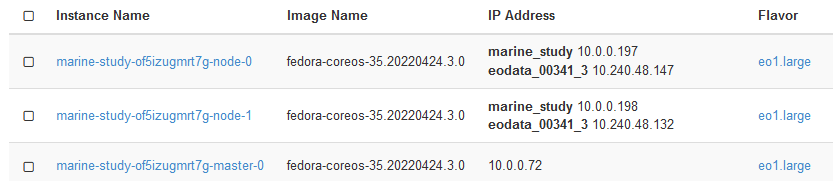
Zwei Arbeiterknoten sind mit dem eodata_-Netzwerk verbunden, der Masterknoten jedoch nicht. Das liegt daran, dass Master-Knoten den Cluster verwalten und nicht mit Zugang zu EODATA ausgestattet sind.
Hier sehen Sie, wie Sie die Software für den EODATA-Zugang über ein Docker-Image bereitstellen können.
Schritt 2 Vorbereiten des Docker-Images der Anwendung
boto3 ist eine Standard-Python-Bibliothek für die Interaktion mit dem S3-Objektspeicher. Der Container, den Sie erstellen, die folgenden Elemente enthalten:
Python und boto3 installiert
Die richtigen Endpunkte für den Zugriff auf EODATA
S3-Anmeldeinformationen für den Zugriff auf diesen Endpunkt.
Mit den folgenden drei Dateien können Sie unsere Anwendung „dockerisieren“, d. h. ihr Docker-Image erstellen und es an DockerHub senden:
eine Python-Datei mit Anwendungscode (app.py in unserem Fall)
die Datei requirements.txt, in der die Abhängigkeiten für die boto3-Bibliothek angegeben sind
ein Dockerfile, das Anweisungen für die Erstellung des Containers enthält
Das auf Python 3.8 basierende Dockerfile wird boto3 installieren und dann die Anwendung ausführen. Im Anwendungscode laden Sie ein Beispiel-Image herunter und lassen den Container 300 Sekunden lang warten. Sie brauchen nur ein paar Sekunden, um zu überprüfen, ob das Image richtig heruntergeladen wurde, also sind fünf Minuten mehr als genug. Erstellen Sie die folgenden drei Dateien und legen Sie sie im selben Verzeichnis ab:
app.py
import boto3
import time
access_key='anystring'
secret_key='anystring'
key='Landsat-5/TM/L1T/2011/11/11/LS05_RKSE_TM__GTC_1P_20111111T093819_20111111T093847_147313_0191_0025_1E1E/LS05_RKSE_TM__GTC_1P_20111111T093819_20111111T093847_147313_0191_0025_1E1E.BP.PNG'
host='http://eodata.cloudferro.com'
s3=boto3.resource('s3',aws_access_key_id=access_key,
aws_secret_access_key=secret_key, endpoint_url=host,)
bucket=s3.Bucket('eodata')
bucket.download_file(key, '/app/image.png')
time.sleep(300)
requirements.txt
boto3==1.21.41
Dockerfile
# syntax=docker/dockerfile:1
FROM python:3.8-slim-buster
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD [ "python3", "-m", "app.py"]
Schritt 3 Erstellen des App-Images und Übertragen auf DockerHub
Um ein Docker-Image zu erstellen und es an DockerHub zu senden, führen Sie den folgenden Befehl in dem Verzeichnis aus, in dem die Dateien gespeichert sind (wählen Sie einen beliebigen Namen für Ihr Repository):
Bemerkung
Abhängig von Ihren Zugriffsrechten müssen Sie dem Docker-Befehlen möglicherweise das Präfix sudo voranstellen.
docker build -t <your-dockerhub-account>/<your-repository-name> .
Stellen Sie sicher, dass Sie bei DockerHub angemeldet sind:
docker login -u <your-dockerhub-username> -p <your-dockerhub-password>
Übertragen Sie dann das Image auf DockerHub (das Repository wird in DockerHub erstellt, wenn es nicht existiert):
docker push <your-dockerhub-account>/<your-repository-name>
Sie können überprüfen, ob das Image gesendet wurde, indem Sie in der Web-GUI von DockerHub prüfen.
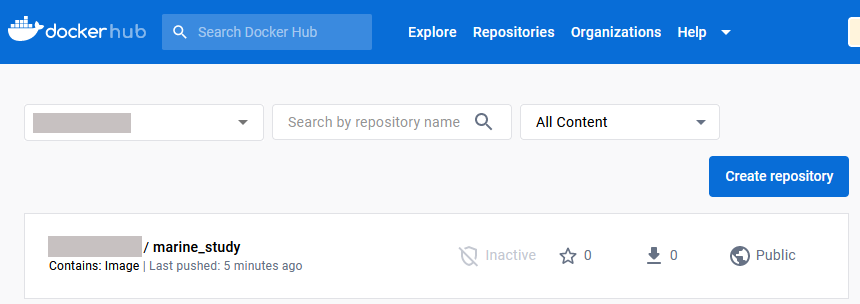
In diesem Bild ist das Repository bereits öffentlich. Wenn es privat ist, machen Sie es öffentlich, indem Sie auf den Namen des Repositorys und dann auf Einstellungen -> Sichtbarkeitseinstellungen klicken.
Schritt 4 Bereitstellung der Anwendung in Kubernetes
Sie haben ein Image erstellt und auf DockerHub platziert und können die Anwendung als Kubernetes-Pod bereitstellen. Normalerweise würden Sie ein YAML-Manifest für den Pod schreiben, aber in diesem Fall verwenden Sie der Einfachheit halber die Befehlszeile. Geben Sie dazu das folgende Snippet ein (erstellen Sie einen beliebigen Pod-Namen):
kubectl run <your-pod-name> --image=<your-dockerhub-account>/<your-repository-name>
Durch die Ausführung des obigen Befehls wird der Pod bereitgestellt, auf dem Ihre containerisierte Python-Anwendung läuft. Da wir 5 Minuten Zeit haben, bevor die Anwendung (und damit auch der Pod) beendet wird, können wir mit dem folgenden Befehl überprüfen, ob das Image heruntergeladen wurde:
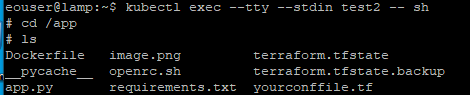
$ kubectl exec --tty --stdin <your-pod-name> -- sh
Dadurch können Sie die Shell des Containers im Pod eingeben. Das Befehlszeilensymbol ändert sich im Pod von $ zu #. Sie können überprüfen, ob das Image in den Pod heruntergeladen wurde, indem Sie zum Verzeichnis /app navigieren und den Inhalt auflisten.
Was als nächstes zu tun ist
Wenn Sie die Richtlinien in diesem Artikel befolgen, können Sie auch komplexere Szenarien implementieren, z. B. durch die Verwendung von Bereitstellungen oder Jobs anstelle von Pods.
Für Produktionsszenarien sollten Sie Ihre S3-Zugangsdaten in einem Kubernetes-Safe oder in einem Passwortsafe wie HashiCorp Vault ablegen. Siehe dazu Installation von HashiCorp Vault auf CODE-DE FRA1-1 Magnum.