Installation und Ausführung von Dask auf einem Kubernetes-Cluster auf der CODE-DE Cloud
Dask ermöglicht die Skalierung von Rechenoperationen entweder in Form von mehreren Prozessen auf einer einzigen Maschine oder auf Dask-Clustern, die aus mehreren Arbeitsmaschinen bestehen. Dask bietet eine skalierbare Alternative zu beliebten Python-Bibliotheken wie z. B. Numpy, Pandas oder SciKit Learn, verwendet aber eine kompakte API.
Der Dask-Scheduler teilt eine Rechenoperationen in kleinere Aufgaben auf, die parallel auf den Arbeitsknoten/Prozessen ausgeführt werden können.
In diesem Artikel werden Sie einen Dask-Cluster auf Kubernetes installieren und Dask-Worker-Nodes als Kubernetes-Pods ausführen. Als Teil der Installation erhalten Sie Zugriff auf eine Jupyter-Instanz, auf der Sie den Beispielcode ausführen können.
Was wir behandeln werden
Dask auf Kubernetes installieren
Zugriff auf das Dashboard von Jupyter und Dask Scheduler
Ausführen einer Beispiel-Rechenaufgabe
Dask-Cluster auf Kubernetes von Python aus konfigurieren
Fehler beheben
Voraussetzungen
Nr. 1 Konto
Sie benötigen ein CODE-DE Konto mit Horizon Interface https://cloud.fra1-1.cloudferro.com/auth/login/?next=/.
Nr. 2 Kubernetes-Cluster in der Cloud
Um einen Kubernetes-Cluster auf einer Cloud zu erstellen, lesen Sie diese Anleitung: Erstellen eines Kubernetes-Clusters mit CODE-DE OpenStack Magnum
Nr. 3 Zugang zur kubectl-Kommandozeile
Die Anweisungen zur Aktivierung von kubectl finden Sie in: Zugriff auf Kubernetes-Cluster nach der Bereitstellung mit Kubectl auf CODE-DE OpenStack Magnum
Nr. 4 Kenntnisse über den Helm
Weitere Informationen zur Verwendung von Helm und zur Installation von Anwendungen mit Helm auf Kubernetes finden Sie unter Einsatz von Helm Charts auf Magnum Kubernetes-Clustern auf der CODE-DE FRA1-1 Cloud
Nr. 5 Python3 auf Ihrem Rechner
Python3 ist auf dem Arbeitsrechner vorinstalliert.
Nr. 6 Grundlegende Kenntnisse über Jupyter und die wissenschaftlichen Bibliotheken von Python
Wir werden Pandas als Beispiel verwenden.
Schritt 1 Installation von Dask auf Kubernetes
Um Dask als Helm-Chart zu installieren, laden Sie zunächst das Dask Helm-Repository herunter:
helm repo add dask https://helm.dask.org/
Anstatt das Chart sofort zu installieren, sollten wir die Konfiguration der Einfachheit halber anpassen. Um alle möglichen Konfigurationen und ihre Standardwerte anzuzeigen, führen Sie aus:
helm show dask/dask
Bereiten Sie die Datei dask-values.yaml vor, um einige der Standardeinstellungen zu überschreiben:
dask-values.yaml
scheduler:
serviceType: LoadBalancer
jupyter:
serviceType: LoadBalancer
worker:
replicas: 4
Dies ändert den Standardtyp für Jupyter und Scheduler im LoadBalancer, so dass sie öffentlich zugänglich sind. Außerdem wird die Standardanzahl der Dask-Worker von 3 auf 4 geändert. Jedem Dask-Worker-Pod werden 3 GB RAM und 1 CPU zugewiesen, wir belassen es bei diesem Standard.
Um das Diagramm bereitzustellen, erstellen Sie den Namespace dask und installieren Sie ihn:
helm install dask dask/dask -n dask --create-namespace -f dask-values.yaml
Schritt 2 Zugriff auf Jupyter und Dask Scheduler Dashboard
Nach dem Installationsschritt können Sie auf die Dask-Dienste zugreifen:
kubectl get services -n dask
Zwei Dienste für Jupyter und Dask Scheduler sind vorhanden. Das Einrichten externer IPs dauert einige Minuten:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dask-jupyter LoadBalancer 10.254.230.230 64.225.128.91 80:32437/TCP 6m49s
dask-scheduler LoadBalancer 10.254.41.250 64.225.128.236 8786:31707/TCP,80:31668/TCP 6m49s
Wir können die externen IPs in den Browser einfügen, um die Dienste anzuzeigen. Um auf Jupyter zuzugreifen, geben Sie zunächst im Anmeldebildschirm das Standardpasswort dask ein. Dann können Sie die Jupyter-Instanz anzeigen:
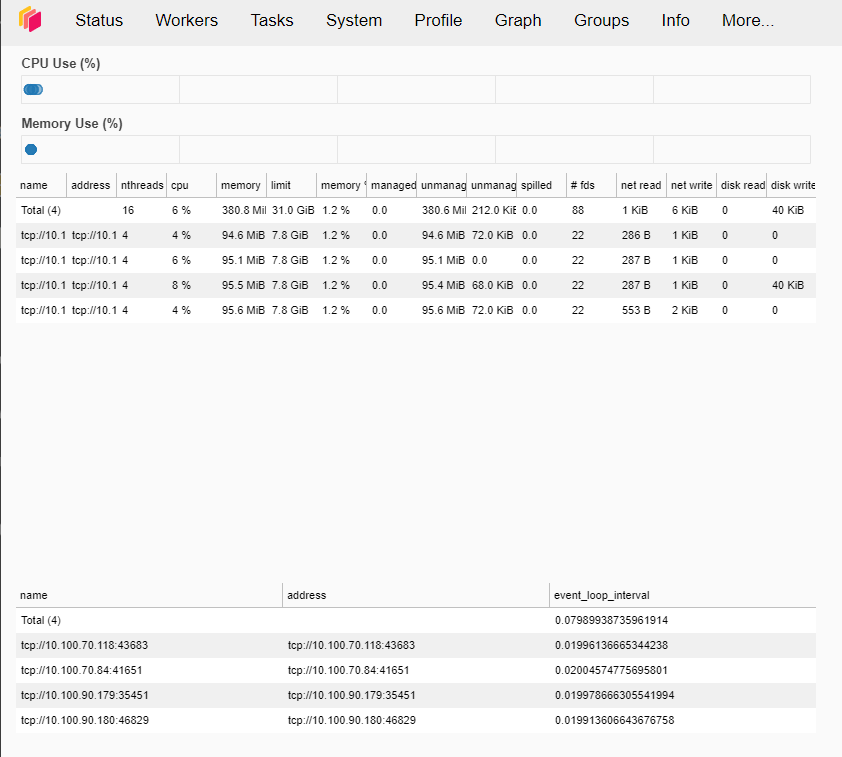
Ähnlich verhält es sich mit dem Scheduler Dashboard: Fügen Sie die floating IP in den Browser ein. Wenn Sie oben auf die Registerkarte „Workers“ klicken, können Sie sehen, dass 4 Worker auf unserem Dask-Cluster ausgeführt werden:
Schritt 3 Führen Sie eine Beispiel-Rechenaufgabe aus
Auf der installierten Jupyter-Instanz sind Dask und andere nützliche Python-Bibliotheken bereits installiert. Um einen Beispielauftrag auszuführen, aktivieren Sie zunächst das Notizbuch, indem Sie auf das Symbol Notizbuch → Python3(ipykernel) auf der rechten Seite des Jupyter-Instanzbrowsers klicken.
Das Beispiel führt Berechnungen in einer Tabelle (Datenrahmen) mit 100k Zeilen und nur einer Spalte durch. Jeder Datensatz wird mit einer zufälligen Zahl von 1 bis 100.000 gefüllt. Die Aufgabe besteht darin, die Summe aller Einträge zu berechnen.
Der Code wird das gleiche Beispiel für Pandas (Einzelprozess) und Dask (parallelisiert auf unserem Cluster) ausführen. Anschließend können wir die Ergebnisse überprüfen.
Kopieren Sie den folgenden Code und fügen Sie ihn in die Zelle im Jupyter-Notebook ein:
import dask.dataframe as dd
import pandas as pd
import numpy as np
import time
data = {'A': np.random.randint(1, 100_000_000, 100_000_000)}
df_pandas = pd.DataFrame(data)
df_dask = dd.from_pandas(df_pandas, npartitions=4)
# Pandas
start_time_pandas = time.time()
result_pandas = df_pandas['A'].sum()
end_time_pandas = time.time()
print(f"Result Pandas: {result_pandas}")
print(f"Computation time Pandas: {end_time_pandas - start_time_pandas:.2f} seconds.")
# Dask
start_time_dask = time.time()
result_dask = df_dask['A'].sum().compute()
end_time_dask = time.time()
print(f"Result Dask: {result_dask}")
print(f"Computation time Dask: {end_time_dask - start_time_dask:.2f} seconds.")
Klicken Sie auf Play oder verwenden Sie die Option Run aus dem Hauptmenü, um den Code auszuführen. Nach ein paar Sekunden wird das Ergebnis unter der Zelle mit dem Code angezeigt.
Some of the results we could observe for this example:
Result Pandas: 4999822570722943
Computation time Pandas: 0.15 seconds.
Result Dask: 4999822570722943
Computation time Dask: 0.07 seconds.
Beachten Sie, dass diese Ergebnisse nicht deterministisch sind und einfache Pandas von Fall zu Fall auch besser abschneiden könnten. Der Overhead für die Verteilung und Sammlung der Ergebnisse von Dask-Arbeitern muss ebenfalls berücksichtigt werden. Eine weitere Optimierung der Leistung von Dask würde den Rahmen dieses Artikels sprengen.
Schritt 4 Konfigurieren des Dask-Clusters auf Kubernetes mit Python
Für die Verwaltung des Dask-Clusters auf Kubernetes können wir eine spezielle Python-Bibliothek dask-kubernetes verwenden. Mit dieser Bibliothek können wir bestimmte Parameter unseres Dask-Clusters neu konfigurieren.
Eine Möglichkeit, dask-kubernetes auszuführen, wäre von der Jupyter-Instanz aus, aber dann müssten wir eine Referenz zu kubeconfig unseres Clusters bereitstellen. Stattdessen installieren wir dask-kubernetes in unserer lokalen Umgebung mit dem folgenden Befehl:
pip install dask-kubernetes
Sobald dies geschehen ist, können wir den Dask-Cluster mit Python verwalten. Als Beispiel wollen wir ihn auf 5 Dask-Knoten hochskalieren. Verwenden Sie nano, um die Datei scale-cluster.py zu erstellen.:
nano scale-cluster.py
fügen Sie dann folgende Befehle ein:
scale-cluster.py
from dask_kubernetes import HelmCluster
cluster = HelmCluster(release_name="dask", namespace="dask")
cluster.scale(5)
Führen sie das Kommando aus:
python3 scale-cluster.py
Mit dem Befehl
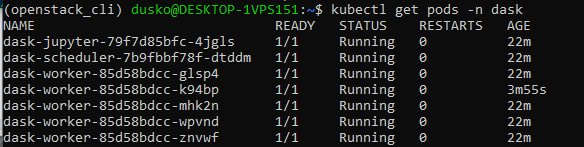
kubectl get pods -n dask
können Sie sehen, dass die Anzahl der Arbeiter jetzt 5 beträgt:
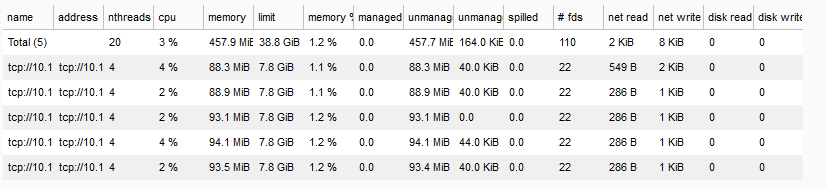
Sie können die aktuelle Anzahl der Arbeitsknoten auch im Dask Scheduler-Dashboard sehen (aktualisieren Sie den Bildschirm):
Beachten Sie, dass die Funktionalitäten von dask-kubernetes auch direkt mit der Kubernetes-API erreicht werden können; die Wahl hängt von Ihren persönlichen Vorlieben ab.
Behebung von Fehlern
Beim Ausführen des Befehls
python3 scale-cluster.py
auf der WSL Version 1, können Fehlermeldungen wie die folgenden erscheinen:

Der Code funktioniert ordnungsgemäß, d. h. er erhöht die Anzahl der Arbeiter auf 5, wie erforderlich. Der Fehler sollte bei WSL Version 2 und anderen Ubuntu-Distributionen nicht auftreten.